Bait, Keep, or Block: A Smarter Way to Handle AI Crawlers
Most advice about AI crawlers comes down to two buttons: block everything, or allow everything. Both are wrong, and for the same reason — they treat every bot as identical when they're nothing alike.
Put Disallow: / in your robots.txt and the well-behaved crawlers obey it — which means you've just removed yourself from the AI answers that fetch live pages and from the training data that teaches models you exist. Leave the door wide open instead, and you're not just welcoming the bots that send traffic your way; you're also feeding bulk scrapers and anything wearing a fake badge.
There's a better way, and it isn't a bigger wall. It's knowing exactly who's at the door, and treating each visitor on its merits.
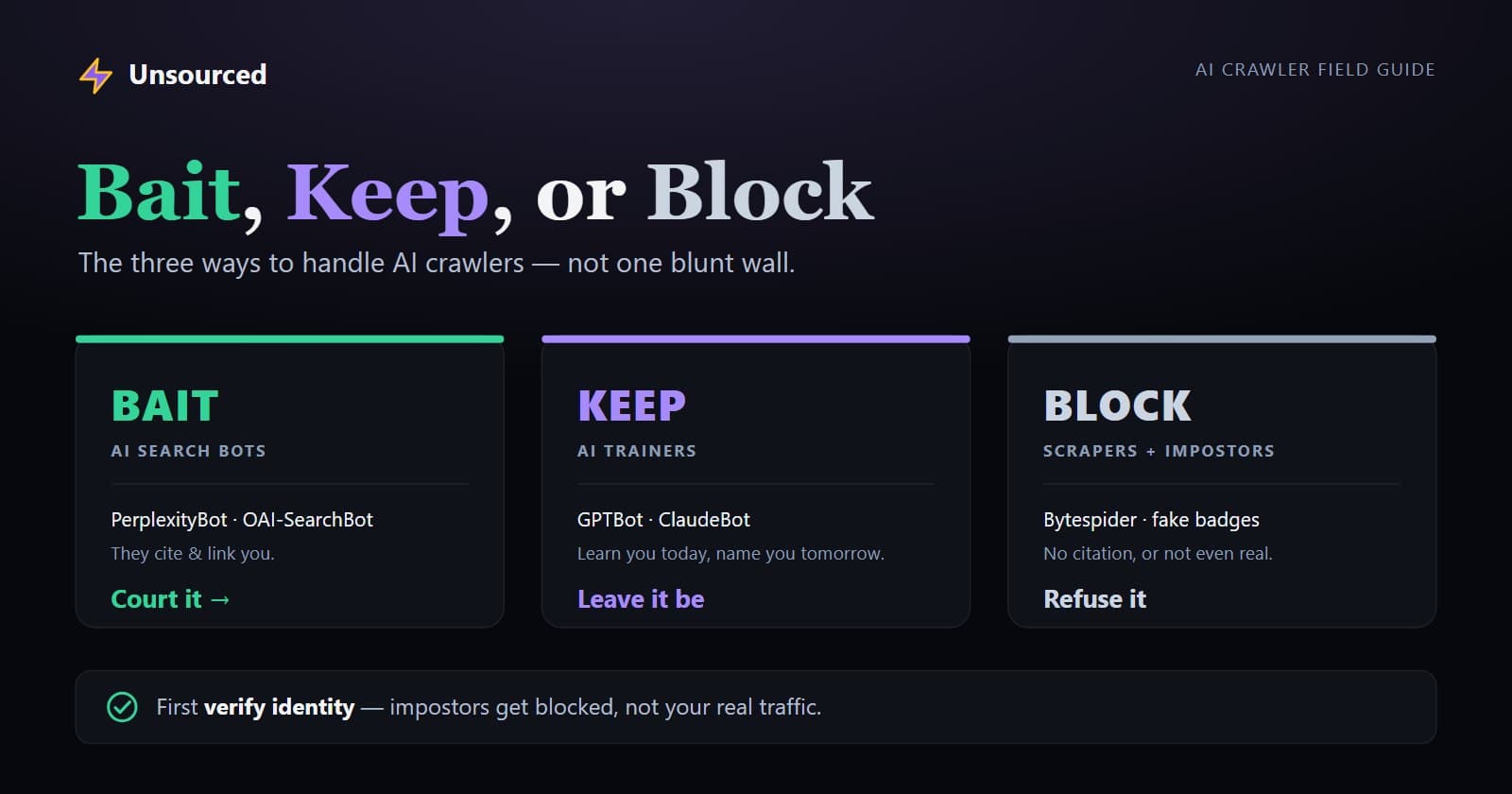
There aren't two kinds of AI crawler. There are three.
The "training vs retrieval" split you usually hear is missing a category, and the missing one matters.
AI Search bots — OAI-SearchBot, PerplexityBot, ChatGPT-User, YouBot. These fetch live pages to answer a user's question right now, and they cite and link what they use, so they can send you real referral traffic. These are the ones you most want to reach. (Two lookalikes to know: Google-Extended and Applebot-Extended aren't crawlers at all — they're robots.txt switches that decide whether Google and Apple may use your content for their AI. The same "court it" instinct applies, but they're permissions, not visitors, and send no traffic of their own.)
AI Trainer bots — GPTBot, ClaudeBot, CCBot, Amazonbot. They don't link you today. They learn from you — and being in the training set is exactly how a model comes to "know" your brand exists and name it later. Blocking these feels productive, but it quietly removes you from the future answers you're trying to win.
Scrapers — Bytespider, Diffbot and similar. Bulk extraction with no citation path back to you. No search result, no link, no learning you'd benefit from.
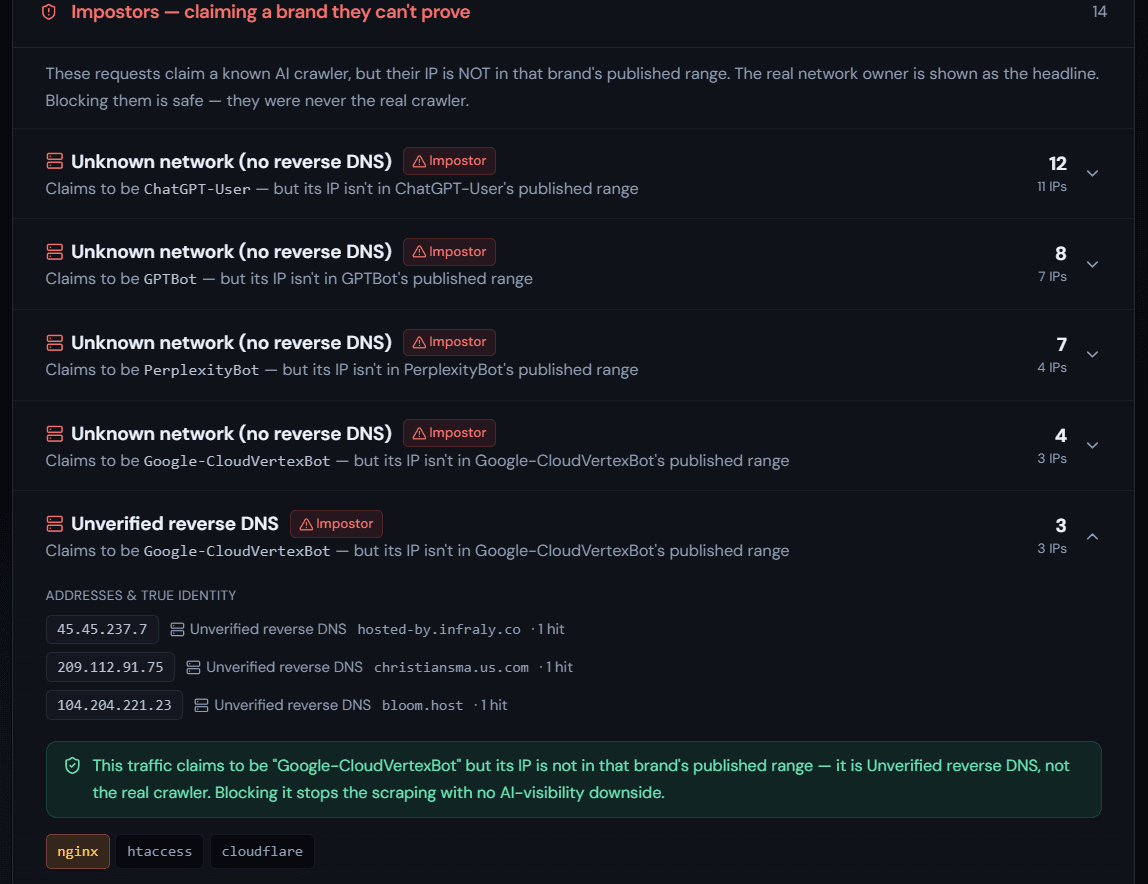
And cutting across all three: Impostors — traffic claiming one of these names that the network evidence contradicts (the subject of our last post). An "impostor" isn't an accusation of motive; it's a fact about identity — it isn't the bot it says it is.
So the real choice was never "block or allow." It's bait the search bots, keep the trainers, block the scrapers and impostors.
Why blanket rules backfire
A single robots.txt directive can't tell those four apart, so it does collateral damage in both directions. Disallow: / turns away the Search bots that would have cited you and the Trainers that would have learned you. Allow-all lets the scrapers and impostors help themselves.
Worse, your server logs can't see the difference between a real PerplexityBot and a rented server in a data centre wearing "PerplexityBot" in its User-Agent. Acting on the name alone, you end up blocking your genuine referral sources while waving the fakes straight through. That's not control — that's firing blind.
Route by verified identity, not by the header
The fix is to verify who each crawler actually is before you decide anything — exactly the network-layer check from the last post: is the IP inside the operator's published range, or does it pass a forward-confirmed reverse-DNS lookup? Either one verifies it; a contradiction marks it an impostor.
This is where Unsourced fits, and it's worth being precise about the boundary: Unsourced doesn't block anything for you. It labels every crawler that hits you — Verified, Impostor or Unverifiable, and AI Search, Trainer or Scraper — and hands you the exact, honest rule to act on it in your own stack (Cloudflare, nginx, or robots.txt). The decision, and the switch, stay yours. (If you want enforcement, that's an optional Cloudflare Worker rule you turn on yourself — off by default, and it fails open so it can never accidentally wall off a real crawler.)
Once you can see true identity, the three moves are simple — and if you want the full reference, we keep a live breakdown of how to handle every major AI crawler:
Bait — your AI Search bots. When a search bot fetches a page, give it the cleanest possible data to work from: clear structure, JSON-LD, obvious entity relationships. It won't guarantee a citation, but it makes your page far easier to quote accurately than a wall of unstructured text.
Keep — your AI Trainers. Leave them be. Their value is delayed, not absent: being learned today is how you get named tomorrow.
Block — scrapers and impostors. No citation upside, or never the real crawler in the first place. These are the safe, deliberate things to throttle or block — and because you've verified them, you're blocking the right targets, not your own traffic.
What this looks like in practice
(A hypothetical, to make it concrete.) Say you run a tech-review site. Your verified logs show four notable visitors: a real GPTBot, a real PerplexityBot, a Bytespider scraper, and an "impostor" claiming to be GPTBot that actually resolves to a rented cloud server.
The routing writes itself:
GPTBot (verified trainer) → keep. It's how the big assistants come to know your site.
PerplexityBot (verified search) → bait. Your "Best of" comparison pages are getting fetched but your specific metrics aren't being cited — so you add a clean comparison summary (structured data) to those pages, giving Perplexity something tidy to quote.
Bytespider (scraper) → block in your WAF if you'd rather not feed it; there's no citation in it for you.
The impostor → block safely. It was never OpenAI, so refusing it costs you nothing real.
Then you wait, and you re-check — does Perplexity start citing the comparison data once it's there? You measure the change rather than assume it. (More on closing that loop in the next post.)
From blunt blocking to selective transparency
This isn't a config you set once and forget. It's a short, repeatable loop: verify who's really crawling you, sort them by what they actually do, serve your best pages in a form the search bots can quote, and measure what changes.
The goal isn't to keep AI out. It's to be deliberately open with the crawlers that pay you back — and deliberately closed only to the ones that don't, or that were lying about who they are.
Want to check a crawler right now? Try the free AI Bot Verifier — a no-signup tool for checking whether a bot hitting your site is the genuine crawler or an impostor. Drop in a bot name or an IP from your server logs, and it checks it against the operator's published ranges and forward-confirmed reverse DNS on the spot, then tells you straight: Verified, Impostor, or Unverifiable.
And when you want the whole picture — every AI crawler that hits your site, labelled and sorted into Search / Trainer / Scraper, each with the exact rule to act on it in your own stack — that's what Unsourced does.
Check your site free →