The GPTBot Mirage: How to Tell Real AI Crawlers From Impostors
Most analytics tools make one quiet assumption that quietly breaks everything: they trust the User-Agent.
When your server logs show a hit from GPTBot or ClaudeBot, that name comes from a header the visitor sends about itself. It's a claim, not a credential. Any scraper can put GPTBot in its User-Agent in one line of code — and many do, precisely because publishers wave through anything wearing a familiar badge.
So when you write a robots.txt rule or a Cloudflare filter based on those names, you may be doing the opposite of what you think: politely standing aside while an anonymous harvester copies your content under a borrowed identity, all while you believe you're tracking the real AI companies.
The fix isn't to trust names harder. It's to stop trusting them at all, and verify identity at the network layer instead.
Two ways to prove a crawler is who it says
Unsourced ignores the User-Agent as proof and runs two independent checks. Either one is enough to verify a crawler — they're belt-and-braces.
Published IP ranges. The major AI operators (OpenAI, Anthropic, Google and others) publish the IP ranges their crawlers operate from. If a request claiming to be GPTBot comes from inside OpenAI's published range, that's a strong, hard-to-fake confirmation.
Forward-confirmed reverse DNS (FCrDNS). This is the check that catches spoofers hiding on rented servers. It works in two moves:
Take the visitor's IP and look up its PTR (reverse-DNS) record to get a hostname.
Then resolve that hostname forward — and only trust it if one of the forward addresses is the original IP, and the hostname belongs to the operator's own domain (e.g. openai.com).
Here's why that's spoof-proof: a PTR record is set by whoever controls the IP, so an attacker on a VPS can make their address claim to reverse-resolve to crawl.openai.com. But they can't make openai.com's real, forward DNS point back at their server. The forged record fails the round-trip. (This is the same method Google and Bing have long recommended for verifying their own crawlers.)
Three honest buckets
Run those checks against your traffic and every AI visitor falls into one of three groups:
Verified — the network evidence backs the claim. A verified GPTBot really is OpenAI. The badge is earned.
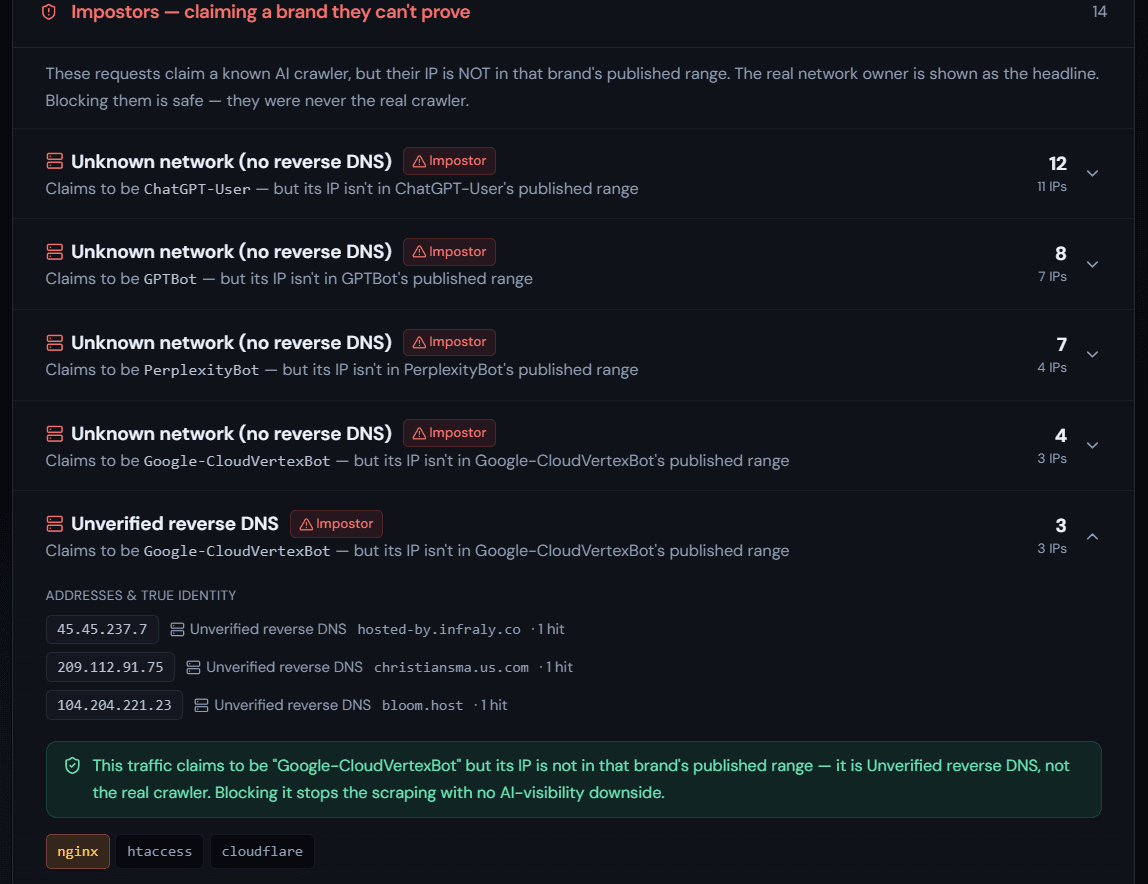
Impostor — the claim is contradicted by the evidence: the IP sits outside the operator's published range, or a forward-confirmed hostname belongs to someone else entirely (claims GPTBot, resolves to an AWS or Hetzner box). Important: this is a statement about identity, not motive. We're not accusing it of anything — we're showing you it isn't who it says it is. What it's doing with that disguise is your call.
Unverifiable — there isn't enough to decide. No published range for that bot name, and no usable reverse DNS to check. Coverage here is genuinely partial: FCrDNS works best on the big crawlers (GPTBot, ClaudeBot), while many smaller bots publish no reverse DNS at all. So rather than guess, we hold these for your review. We never label something an impostor just because we couldn't verify it — absence of proof isn't proof of a lie.
That last principle matters. The point of the verdict is honesty in both directions: when a crawler is real, the truth becomes the headline; when a crawler is faking it, the real network owner becomes the headline and the borrowed name gets demoted to a footnote.
We show you the evidence. You stay in control.
One deliberate boundary: Unsourced is an observation layer, not a firewall. We don't block anything on your behalf, and we don't sit in your traffic path making unilateral decisions.
What we give you is the proof: which IPs are verified, how often impostors are hitting you, who actually owns the addresses behind the borrowed badges. With that, you update your own stack — Cloudflare, nginx, robots.txt — knowing exactly which crawlers earn their access and which are just wearing the uniform (a tactical framework we will break down explicitly in our upcoming technical guide). The decision stays yours; we just make sure it's an informed one.
The mirage clears the moment you stop reading names and start checking origins. Stop managing your AI footprint on trust, and start managing it on verified identity.
Want to see who's really crawling your site ? Unsourced verifies every AI crawler that hits your pages — and shows you the ones that aren't who they claim to be.